Where Do Large Learning Rates Lead Us?
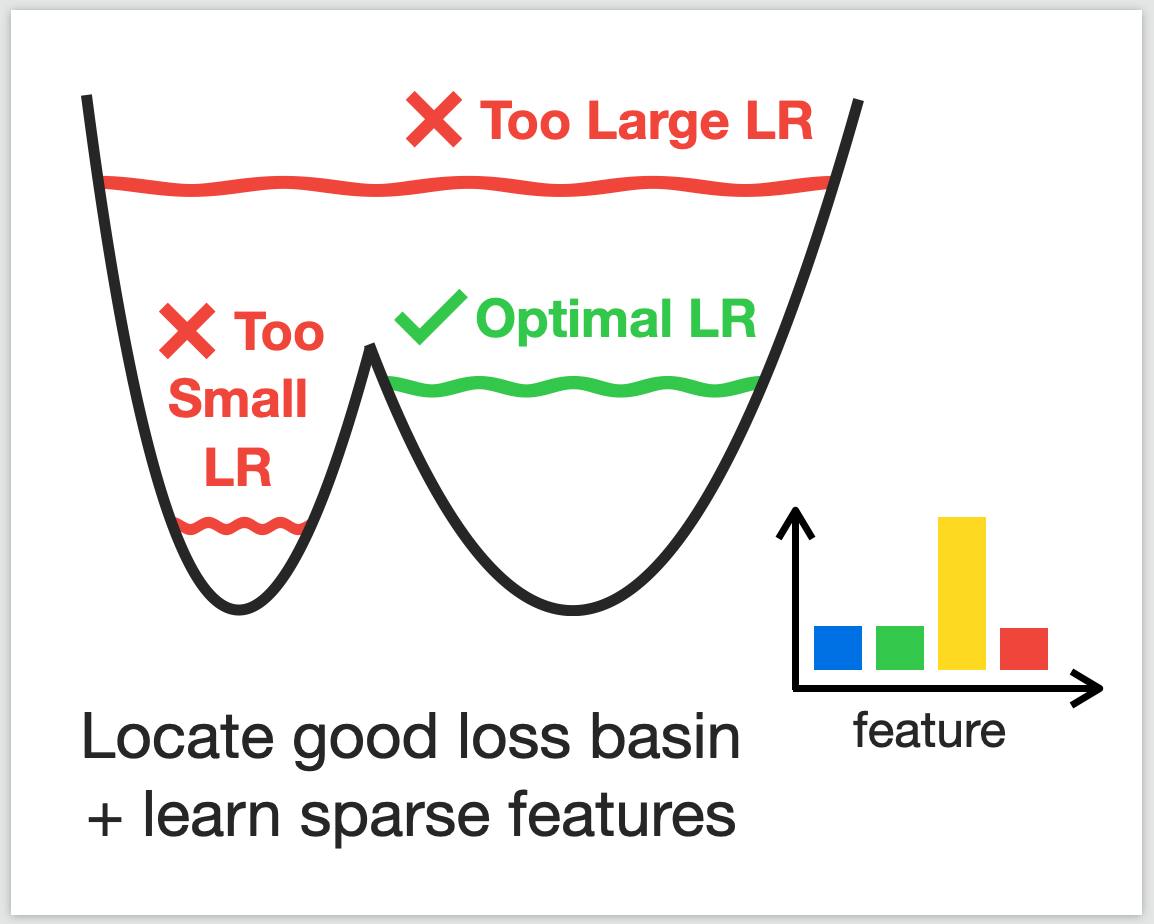
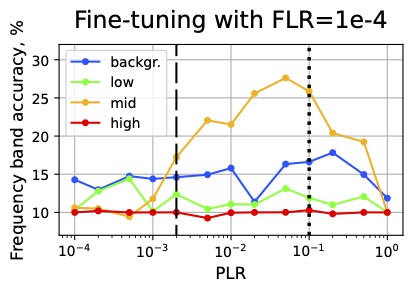
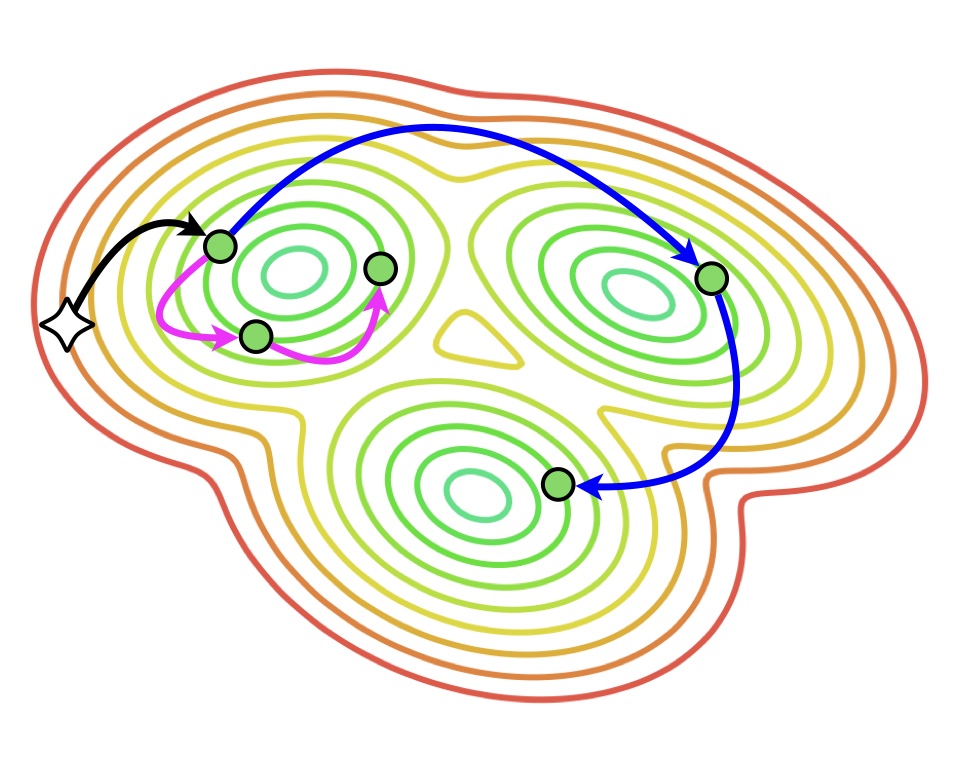
Ildus Sadrtdinov*, Maxim Kodryan*, Eduard Pokonechny*, Ekaterina Lobacheva†, Dmitry Vetrov† We show that only a narrow range of large LRs is beneficial for generalization and analyze it from the loss landscape and feature learning perspectives. |